

since the gpt-4o demo from openai a few weeks ago (this one) - the ai doomers seem to be out in full force. there's good reasons to be cautious about the future of ai but there's also a lot of misinformation about how chatgpt actually works.
i thought I'd write up a short overview of what's actually going on under the hood so you can see for yourself and make your own mind up about the future risks, limitations and opportunities we can expect from these types of models.
at the very least, i hope it's somewhat interesting to know how the fastest growing product ever made actually works.
it's just guessing the next word
whenever you ask chatgpt a question, you'll notice that answers come in bit by bit, almost one word at a time. that's because all the ai is doing is essentially predicting what the next word should be, given what text has been given to it so far (your prompt). for example, if you gave it the text 'the best thing about ai is' - it will produce a ranked list of words that could come next, along with some probabilities.

it then picks a word, loops round and does the same thing again and again. that’s how it generates text. it's pretty remarkable that the text it writes feels human-like, even though it’s just statistically picking the next word.
ok so what word should it pick?
you might think, that chatgpt always picks the word with the highest 'probability' that was assigned to it. the issue with that is that you tend to get really monotone, dull and uncreative af text that's not very human like. humans have variability and a bunch of other factors that make our writing, well human.
so instead, it sometimes picks from lower-ranked words to keep things interesting and varied. this randomness is the reason that if you ask chatgpt the same thing twice, you’ll get different answers. this 'randomness' is captured in a parameter called “temperature” that tweaks how often it picks those lower-ranked words. basically, chatgpt is all about mixing it up to keep the text fresh and lively.
here's what text might sound like with temperature set to 0.

and here's some text which temperature set to 0.8.

so where do these probabilities actually come from?
ok so lets start by taking a random body of text - say all of the text in the english language.
we can start by working out how often each word comes up across all this text and assign probabilities. but if we generated some text randomly using these probabilities we'd get some sort of incoherent drivel like this:

the issue with this is that we're picking words in isolation & separately. instead we need to think about words in groups. for example we could calculate the probabilities of every 2 word combination in the english language and generate text using these probabilities. for example, starting with the word cat, if we continue to add 2 word combinations based on their probabilities in the english language, these are some variations of what you might get. it's better, but still not great.

so now you might think - ok, what if i calculated probabilities for not just single words, or pairs of words but combinations of words up to the length of an essay - you could recreate a chatgpt. i.e. you'd be able to create essay-length sequences of words with the “correct overall essay probabilities”. but here’s the problem: there just isn’t even close to enough english text that’s ever been written to be able to figure out those probabilities.
why we can't just figure out all the probabilities
in a crawl of the entire web there might be hundreds of billions of words, and digitized books could add another hundred billion. with around 40,000 commonly used words, the number of possible two-word combinations would be 1.6 billion (40,000 squared). If you consider sequences of three words, the number becomes 64 trillion (40,000 cubed). for essay fragments made up of 20 words, the number of possible combinations is mind-bogglingly large, much more than the number of particles in the universe—they could never all be written down. this means we can't estimate the likelihood of all these word sequences from the available text we have - it's a matter of data scale.
so, what can we do? the big idea is to develop a model that can estimate the probabilities of various word sequences, including those we have not encountered before. at the core of ChatGPT is a model (that people call a large language model) designed to achieve this goal.
ok so lets use models
so if we can't figure out the 'actual' probabilities because there's not enough text out there, we need to use a model to estimate these probabilities.
a model is just a toy version of something real, it's a mathematical guess about how the real world works. in our case, we need to guess the probabilities of what word to add next, given a long sequence of text.
models can really take any mathematical form you want. lets start with a simple example. imagine we have some real data on how long it takes a cannonball to fall from various floor heights.
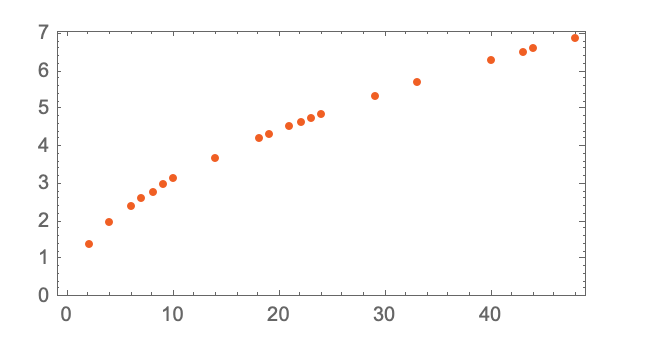
we can try and use a mathematical expression to guess these numbers. we could use a linear expression (of the form y = mx + c) and we could get something which is pretty good at matching the real data.
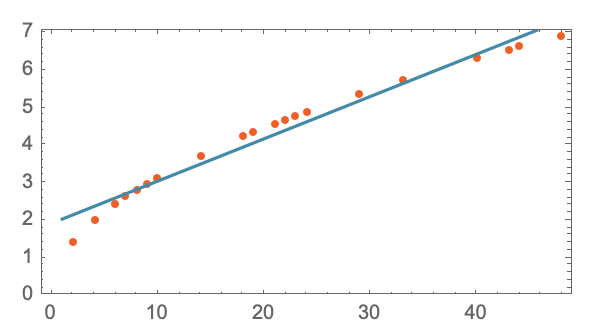
or we could use a quadratic (of the form y = a + bx + bx^2) and we'd get an even better model.
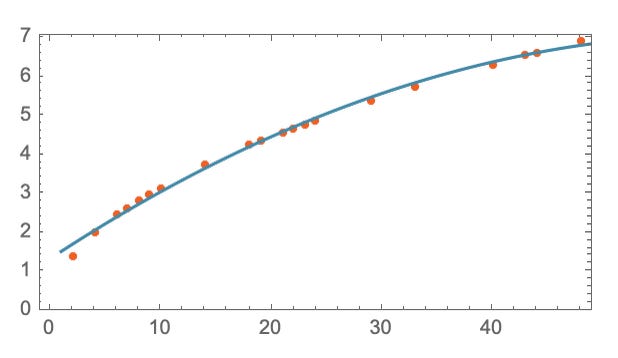
we can then just tweak each of these parameters or 'knobs' like the value of a, b and c to try and get a better fit.
in the case of chatgpt, we use a specific formal of model called a neural net which has hundreds of billions (if not trillions) of these 'knobs' which we can adjust.
ok so i get what a model is now - what's a neural net
a neural net is just a type of model that happens to be good at making predictions for human like tasks (e.g. writing text). neural nets were invented in the 1940s and are a style of model which take inspiration from the way our brains work.
in human brains, there are about 100 billion neurons, or nerve cells. neurons are connected togehter in complex structures like tree branches. each neuron can create an electrical signal up to a thousand times a second and send these signals on towards other neurons. basically, whether a neuron sends out a signal at any moment depends on the signals it got from other neurons, with some connections having more influence than others.
an artificial neural net looks kind've similar. it's a connected collection of 'neurons' arranged in layers like this.
each neuron is like a little calculator that does simple math. to use the network, we just give it some numbers (like our coordinates x and y). the neurons in each layer do their math and pass the answer to the next layer, until we get the final result at the bottom.

the neural net of chatgpt looks just like this except it has hundreds of billions of neurons. each time chatgpt writes a word, all it's doing is 3 things: firstly, taking the text it's been given an turning it into some array of numbers [x1, x2...]. secondly, it ripples those numbers through the hundreds of billions of neurons and their respective calculations. finally, it takes the output array of numbers and converts it back into probabilities of what word to write next.
but how do we know what weights to use in the neural net
in the examples we've talked about so far - we assume we already have the values of these 'knobs' or weights that the model should use. this implies that the model already 'knows' how to do certain tasks and is already good at prediction. the question is - how do we work out these weights from scratch, especially when we've got hundreds of billions of them.
this is what makes neural nets special. we can train them by giving them lots of examples of the task at hand to figure out these weights.
lets start with a simple example. imagine we're trying train a basic neural net to model this underlying mathematical function:

we can use a simple neural net that takes one input (x) and generates one output (y) with 7 neurons in the middle layers. if we randomly pick some weights, we get outputs which look like this.
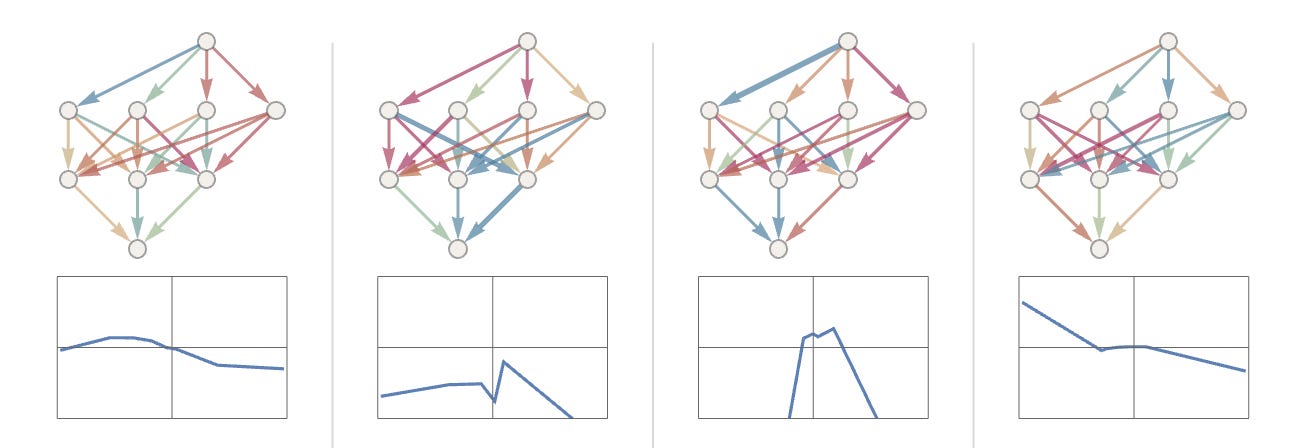
instead of randomly picking weights we can 'train' the model on lots of examples of real 'x' and 'y' values from the true function. each time we give our neural net an input of x and it outputs some value, we can compare it to the 'real' y and see how far away it was. then we simply tweak the weights so that it gets closer to the real y each time. if we repeat this a million times, the models weights gradually adjust so that it can estimate the 'real' function pretty well for all values of x.

so all that training a model is. it's getting a bunch of real examples and at each step in this training, the weights in the network are slowly changed. eventually, we get a network that does what we want. so, how do we change the weights? the main thing is to check how far off we are from the real example, and then update the weights to get closer to the right answer.
ok i think i get it, how does this all relate back to chatgpt
so what does chatgpt actually do? think of it like this: its main job is to continue writing text in a way that makes sense, based on what it has learned from reading a giant pile of text from the internet.
it works in three simple steps. first, it looks at the words that it has so far and turns them into a bunch of numbers (it's not important how it does this, so don't worry about this part for now). then, it does some math with these numbers, like how a brain works, to get a new bunch of numbers (i.e. it runs the numbers through the neural net). finally, from these final output numbers it turns them back into probabilities of what word to pick next.
an important thing to remember is that every part of this process is done by a neural net. this network got really smart by practicing with lots of text, so it learned almost everything by itself. nothing was explicitly given to it. all we did was collect a bunch of examples of real text, asked it to predict what should come next, told it whether it was close or not, then adjusted the weights of the neural net and repeated.
the magic of neural nets is that given enough data we can train them to learn pretty much anything from how to turn text into images or learning how to write songs etc.
some thoughts on what chatgpt is good at what it’s bad at
human language always used to seem like this incredibly complex system that only humans could figure out with our incredibly sophisticated brains. some people might have thought that brains have more than just networks of neurons, maybe some new kind of physics we don't know about yet. but now with chatgpt, we learned something important: a simple, artificial neural network with about as many connections as a brain has neurons can do a really good job of making human language.
imo the explanation is that human language is simpler than it looks. this means that chatgpt, even with its basic neural net structure, can understand human language and the way we think. and that during its training, chatgpt was able to discover the implicit patterns in language and thinking that allows it to generate text that's so human like. it's crazy - chatgpt has basically figured out a 'law of language' (intrisically coded it via weights in a neural net). it makes you think what other patterns and laws are out there that we haven't been able to figure out yet.
however, there's still certain things neural nets aren't great at on their own (at least not without access to external tools). for example, looking back at our example of training a neural net to model a simple mathematical equation. it doesn't actually 'know' the explicit function - it's just been able to kind've figure out what it looks like given loads of examples. that's why if you go outside the training set you can sometimes get wacky results.

so at least for now, neural nets are great at human like tasks but not so great at 'maths' type tasks with seemingly explicit steps that one needs to go through.